
Many professionals believe voice recognition AI is simply speech-to-text conversion, but this technology involves far more complex architecture. Modern voice recognition systems integrate speech recognition engines, natural language understanding modules, and backend orchestration layers to deliver meaningful interactions. This guide breaks down the core components, performance benchmarks, real-world challenges, and emerging trends that developers, content creators, and business analysts need to understand when evaluating or building voice AI solutions.
Table of Contents
- Understanding The Core Components Of Voice Recognition AI
- Evaluating Accuracy And Performance: Benchmarks And Metrics
- Addressing Real-World Challenges In Voice Recognition AI
- Future Trends And Practical Applications Of Voice Recognition AI
- Explore Powerful Voice Recognition AI Solutions With Sofia🤖
- Frequently Asked Questions
Key takeaways
| Point | Details |
|---|---|
| Core architecture | Voice recognition AI combines speech-to-text engines, natural language understanding, and backend processing to execute commands. |
| Performance metrics | Word error rate (WER) and throughput measure accuracy and processing speed in real-time applications. |
| Production challenges | Noise interference, accent variability, and concurrency limitations affect deployment reliability. |
| Future innovations | Large language models and transformer architectures enable contextual understanding and natural conversation flows. |
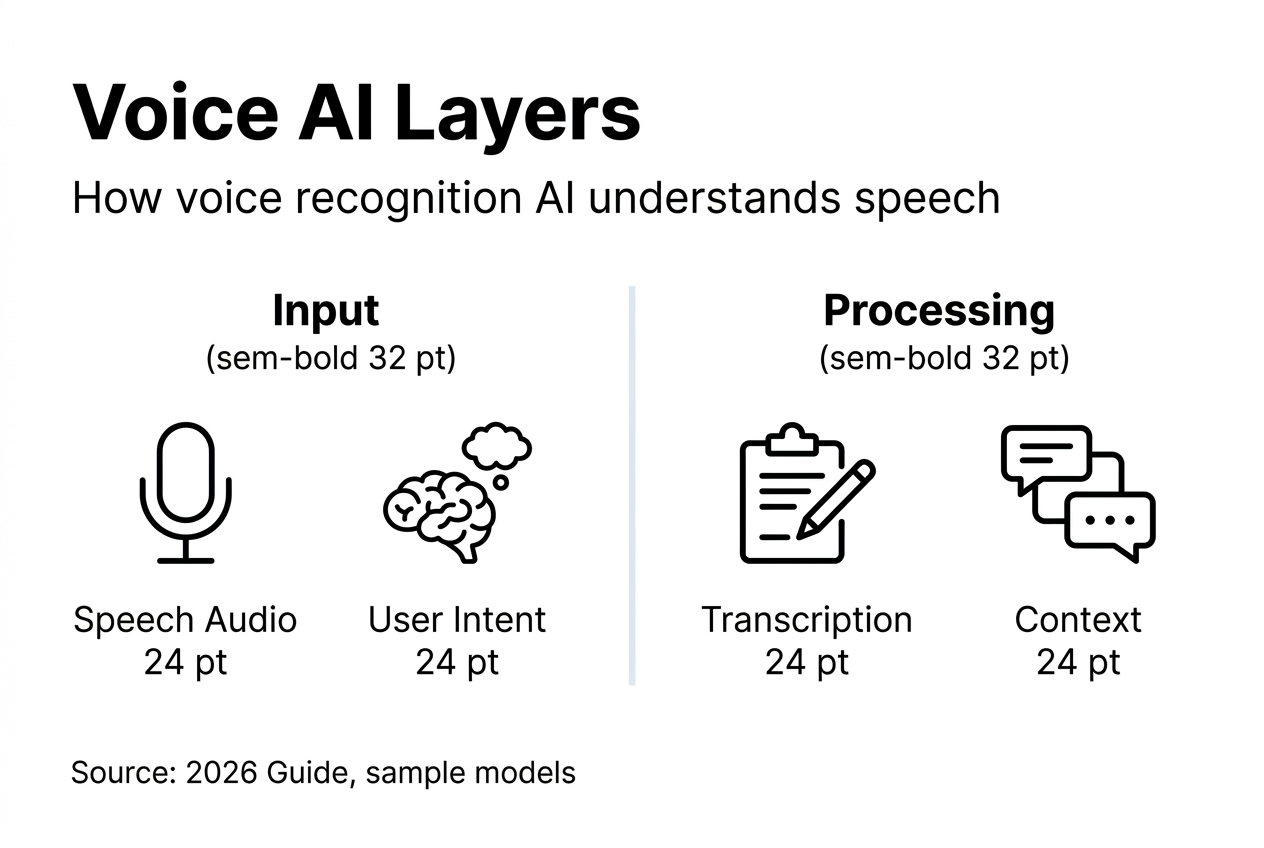
Understanding the core components of voice recognition AI
Voice recognition AI operates through multiple interconnected layers that work simultaneously to process spoken input. AI voice assistants rely on many components to function seamlessly, from initial audio capture to final response generation.
The first layer involves speech recognition, which converts audio into text using acoustic models trained on thousands of hours of diverse speech samples. Deep learning algorithms analyze sound waves, identifying phonemes and word boundaries with increasing precision. This process happens in milliseconds, establishing the foundation for all subsequent processing.
Natural language understanding interprets the transcribed text to extract user intent and contextual meaning. You might say "play something upbeat," and the system must determine you want music, not a video, and identify your mood preference. This layer uses semantic analysis and entity recognition to bridge the gap between raw text and actionable commands.
Backend orchestration executes the interpreted commands by connecting to relevant services and databases. For music requests, it queries streaming platforms. For information retrieval, it searches knowledge bases or external APIs. This coordination layer ensures the system delivers appropriate responses based on user needs.
Machine learning continuously refines system performance by analyzing user interactions and outcomes. Every conversation provides training data that helps models better recognize speech patterns, understand context, and predict user preferences. This adaptive capability separates modern AI-powered personal assistant platforms from static rule-based systems.
Pro Tip: Deep learning neural networks can analyze vocal tone and emotional context, not just words. This capability enables voice AI to detect frustration, urgency, or satisfaction, allowing for more empathetic and appropriate responses in customer service applications.
Key technical components include:
- Acoustic models that map audio signals to phonetic representations
- Language models that predict word sequences and correct recognition errors
- Intent classifiers that determine user goals from natural language
- Dialog managers that maintain conversation context across multiple turns
- Response generators that formulate natural, contextually appropriate replies
Evaluating accuracy and performance: benchmarks and metrics
Professionals evaluating voice recognition systems need objective measurements to compare solutions and predict real-world performance. Accuracy is measured by Word Error Rate, which calculates the percentage of incorrectly transcribed words in test samples. A system with 5% WER transcribes 95 words correctly out of every 100, while 1% WER represents near-human accuracy.
Processing speed matters just as much as accuracy in practical applications. Speed is measured by throughput, typically expressed as how many audio hours the system can process per hour. Real-time applications require throughput rates at or above 1.0, meaning one hour of audio processes in one hour or less.
The Open ASR Leaderboard compares 60+ ASR systems across multiple datasets, providing standardized benchmarks that reflect diverse accents, recording conditions, and vocabulary domains. This public resource helps developers and analysts identify which models excel in specific scenarios, from clean studio recordings to noisy call center environments.
Architectural choices create fundamental tradeoffs between accuracy and efficiency. Conformer encoders with LLM decoders achieve best accuracy but process audio more slowly due to computational complexity. Lightweight models sacrifice some precision for faster inference, making them suitable for mobile devices or high-volume applications where speed outweighs marginal accuracy gains.
Pro Tip: Test voice recognition systems with audio samples that match your actual use case. A model excelling on broadcast news might underperform on conversational speech with overlapping speakers, background music, or domain-specific terminology. Always validate benchmark claims against your specific deployment conditions.
Common benchmark datasets and their characteristics:
| Dataset | Audio Type | Challenge |
|---|---|---|
| LibriSpeech | Audiobooks | Clean speech, standard accents |
| CommonVoice | Crowdsourced | Accent diversity, quality variation |
| AMI | Meetings | Overlapping speakers, far-field audio |
| TED-LIUM | Lectures | Technical vocabulary, presentation style |
Understanding these metrics enables informed decisions when selecting AI personal assistant technology for specific business requirements. Balance accuracy needs against latency constraints and computational resources available in your deployment environment.
Addressing real-world challenges in voice recognition AI
Deploying voice recognition systems in production environments exposes challenges rarely evident in controlled testing scenarios. Background noise obscures speech, reducing transcription accuracy even in systems that perform well on clean audio. Traffic sounds, office chatter, mechanical hum, and music all interfere with the acoustic signal, forcing recognition engines to distinguish speech from competing audio sources.
Regional accents and speech patterns present persistent accuracy challenges across all voice AI systems. Models trained primarily on standard American or British English struggle with non-native speakers, regional dialects, and code-switching between languages. This limitation affects global deployments and reduces accessibility for diverse user populations.

Latency requirements create significant technical constraints for natural voice interactions. Conversational turn-taking is expected within 300–600ms, matching human conversation patterns. Delays beyond this threshold feel unnatural and frustrate users, yet achieving sub-second response times requires optimized infrastructure and efficient models.
Scalability issues emerge when systems move from proof-of-concept to production scale. Most Voice AI demos are tested with one user, but production systems fail at 10–30 concurrent calls due to resource contention, memory limitations, and network bottlenecks. Planning for peak load scenarios requires different architectural approaches than handling average traffic.
Mitigation strategies for common deployment challenges:
- Deploy noise reduction algorithms and echo cancellation before speech recognition processing
- Use directional microphones or microphone arrays to focus on primary speakers
- Implement accent adaptation through transfer learning on regional speech datasets
- Cache common queries and responses to reduce processing latency
- Design horizontally scalable architectures with load balancing across multiple instances
- Monitor system performance continuously to identify degradation before user impact
Awareness of these practical limitations helps developers build more robust voice AI system scalability solutions. You need contingency plans for handling recognition failures gracefully, including confirmation dialogs, alternative input methods, and clear error messaging when the system cannot understand user requests.
Future trends and practical applications of voice recognition AI
Emerging technologies are fundamentally reshaping what voice recognition AI can accomplish beyond simple command execution. Large language models enable machines to understand, reason, and interact naturally, moving from rigid command-response patterns to flexible, contextual conversations. These advances allow voice assistants to handle ambiguous requests, maintain multi-turn dialog context, and provide nuanced responses that consider user history and preferences.
Generative AI capabilities expand voice recognition applications into creative and analytical domains. Instead of retrieving pre-written responses, modern systems can compose emails, summarize documents, generate content ideas, and explain complex concepts in real time. This shift transforms voice AI from an interface layer into a collaborative tool that augments human thinking and productivity.
Transformer architectures have become the dominant paradigm for both speech recognition and language understanding tasks. These models process entire utterances simultaneously rather than sequentially, capturing long-range dependencies and contextual relationships that earlier approaches missed. The result is more accurate transcription and better comprehension of user intent.
Practical applications across industries demonstrate the breadth of voice recognition AI utility:
- Customer support automation: Voice AI handles routine inquiries, troubleshooting steps, and account management tasks without human intervention, reducing wait times and operational costs while escalating complex issues to human agents.
- Content creation workflows: Professionals dictate articles, reports, and creative writing faster than typing, with AI assistants suggesting improvements, fact-checking claims, and formatting documents automatically.
- Accessibility solutions: Voice interfaces provide computer access for users with mobility impairments, visual disabilities, or learning differences, democratizing technology access across diverse populations.
- Workflow automation: Voice commands trigger complex multi-step processes like generating reports, scheduling meetings with constraint checking, or pulling data from multiple systems into unified dashboards.
- Real-time translation: Voice AI transcribes and translates conversations simultaneously, enabling communication across language barriers in business meetings, customer interactions, and international collaboration.
Professionals should evaluate how these capabilities align with organizational needs and user expectations. LLM and GenAI-based assistants offer unprecedented flexibility, but implementing them effectively requires understanding their strengths, limitations, and appropriate use cases. Focus on applications where voice interaction provides genuine value over traditional interfaces, rather than adding voice features simply because the technology exists.
Explore powerful voice recognition AI solutions with Sofia🤖
Professionals seeking production-ready voice recognition AI can leverage Sofia🤖, which integrates the advanced components and emerging technologies discussed throughout this guide. The platform provides access to over 60 state-of-the-art AI models, including GPT-4o, Claude 4.0, and Gemini 2.5, all supporting natural voice interactions with speech recognition capabilities.
Sofia🤖 addresses real-world deployment challenges through enterprise-grade infrastructure designed for scalability and reliability. The platform handles concurrent users efficiently while maintaining the low-latency responses essential for natural conversations. GDPR compliance and enterprise encryption protect sensitive voice data, meeting security requirements for professional and organizational deployments.
Developers, content creators, and business analysts benefit from Sofia🤖's versatile toolset that extends beyond basic transcription. Document analysis for PDFs and images, real-time streaming responses, and team collaboration capabilities make it a comprehensive solution for diverse workflows. Custom AI profiles allow organizations to tailor voice interactions to specific use cases and domain requirements.
Explore how Sofia AI-powered assistant can enhance your productivity through intelligent voice recognition technology that adapts to professional needs across industries.
Frequently asked questions
What is voice recognition AI?
Voice recognition AI is technology that converts spoken language into text and interprets user intent to execute commands or provide information. It combines speech recognition engines, natural language understanding modules, and backend systems that connect to services and databases. Modern voice AI goes beyond simple transcription by analyzing context, maintaining conversation history, and adapting responses based on user preferences and previous interactions.
How do large language models enhance voice recognition AI?
Large language models and transformer architectures enable natural understanding, reasoning about ambiguous requests, and contextual responses that feel conversational rather than scripted. They allow voice assistants to handle complex multi-turn dialogs, infer unstated user needs, and provide nuanced answers that consider conversation history. This advancement transforms voice AI from command executors into collaborative thinking partners that adapt to individual communication styles.
What challenges does voice recognition AI face in noisy environments?
Background noise and varying audio quality obscure speech, forcing recognition systems to separate voice signals from competing sounds like traffic, conversations, or music. Solutions include implementing noise reduction algorithms that filter environmental sounds, using directional microphones that focus on the primary speaker, and training models specifically on noisy audio samples. Advanced systems employ multiple microphones in array configurations to spatially isolate voice sources from background interference.
How is voice recognition AI evaluated for accuracy?
Accuracy in ASR is measured by Word Error Rate, which calculates the percentage of transcription mistakes across test datasets. Lower WER indicates higher accuracy, with 5% WER meaning 95 words transcribed correctly per 100 spoken. Professional systems achieve 1-3% WER on clean audio but may show higher error rates with accents, technical vocabulary, or poor recording conditions. Benchmark datasets like LibriSpeech and CommonVoice provide standardized testing environments for comparing different voice recognition solutions.