
TL;DR:
- AI-enabled attacks increased by 89% in 2025, highlighting gaps in traditional security tools.
- Advanced AI security is a distinct discipline focusing on model, data, and lifecycle threats.
- Frameworks like NIST AI RMF, MITRE ATLAS, and OWASP guide organizations to build resilient defenses.
AI-enabled attacks have surged 89% in 2025, and most organizations are still relying on security stacks built for a world without machine learning models, autonomous agents, or large language models running inside their infrastructure. That gap is dangerous. Legacy tools were designed to protect networks and endpoints, not to detect when a model's training data has been quietly poisoned or when a prompt injection attack is hijacking an AI agent mid-task. This guide breaks down what advanced AI security actually means, which frameworks should anchor your strategy, what the real threat landscape looks like in 2026, and what practical controls your team can deploy right now.
Table of Contents
- Defining advanced AI security: Scope, lifecycle, and why it matters
- Core frameworks: NIST AI RMF, MITRE ATLAS, and OWASP Top 10 for LLMs
- Threats and attack vectors: What to watch for in modern AI deployments
- Practical mitigation strategies for defending AI systems
- A fresh perspective: Why advanced AI security isn't about perfection—it's about resilience
- Taking the next step toward secure, enterprise-grade AI
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Advanced AI security defined | It protects AI systems from unique adversarial threats, attacks, and supply chain risks across the model lifecycle. |
| Frameworks guide defense | NIST AI RMF, MITRE ATLAS, and OWASP Top 10 LLMs are industry benchmarks for structuring enterprise AI security. |
| Key threats are evolving | Attacks like prompt injection and RAG poisoning demand proactive, adaptive organizational response. |
| Resilience over perfection | Since perfect defense is impossible, focus on robust, agile, and continuously improving security postures. |
| Best practices available | Effective mitigations include adversarial training, robust monitoring, and secure supply chain controls tailored for AI. |
Defining advanced AI security: Scope, lifecycle, and why it matters
Advanced AI security is not just "cybersecurity with AI bolted on." It is a distinct discipline. Specialized practices across the AI lifecycle target adversarial threats including model attacks, supply chain compromises, and AI-specific vulnerabilities that have no equivalent in traditional IT security. Understanding this distinction is the first step toward building a posture that actually holds up.
The scope covers four primary threat categories that security teams need to internalize:
- Adversarial inputs: Carefully crafted data designed to fool a model into producing wrong or harmful outputs, without the attacker ever touching the model directly.
- Data and model poisoning: Injecting corrupted data into training pipelines so the model learns flawed or malicious behavior from the start.
- Model extraction: Querying a model repeatedly to reverse-engineer its architecture or training data, effectively stealing intellectual property.
- Supply chain attacks: Compromising third-party datasets, pre-trained models, or ML libraries before they ever reach your environment.
What makes this harder than traditional security is the lifecycle dimension. You need security controls at every stage: data collection, labeling, training, validation, deployment, and ongoing inference. Most organizations lock down deployment but leave training pipelines wide open.
"An AI system is only as trustworthy as the data it was trained on and the pipeline that produced it. Securing the model without securing the pipeline is like locking the front door and leaving the back window open."
Real-world incidents make the stakes concrete. The ShadowRay attack exploited a vulnerability in the Ray distributed computing framework used for AI workloads, giving attackers access to production AI infrastructure across multiple organizations. The Morris II Worm demonstrated that generative AI systems could be weaponized to propagate malware through AI-to-AI communication, a threat vector that simply did not exist five years ago.
Traditional security tools fall short because they rely on signatures, rules, and known-bad indicators. AI threats are statistical, probabilistic, and often invisible to signature-based detection. NIST guidance on AI system security confirms that new evaluation methods are needed specifically for AI's adaptive attack surface. If you are building an AI for business strategy, understanding this scope is non-negotiable. And if your organization handles personal data through AI systems, your AI data privacy obligations are directly tied to these same lifecycle risks.
Core frameworks: NIST AI RMF, MITRE ATLAS, and OWASP Top 10 for LLMs
With the scope defined, the next question is: what structures should guide your defenses? Three frameworks have emerged as the foundation of modern AI security practice, and NIST AI RMF, MITRE ATLAS, and OWASP Top 10 for LLMs together cover governance, adversarial tactics, and application-layer risks.
NIST AI Risk Management Framework (AI RMF) organizes AI risk across four functions: Govern, Map, Measure, and Manage. Govern establishes organizational accountability and policy. Map identifies where AI is deployed and what risks apply. Measure quantifies those risks using metrics and testing. Manage puts controls and response plans in place. The NIST AI RMF resources provide playbooks for each function, making this the right starting point for enterprise-level policy alignment.
MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems) is the practitioner's framework. It catalogs 16 adversarial tactics, 84 techniques, and 32 mitigations specifically for AI and ML systems. Think of it as ATT&CK for AI. Security teams can use the MITRE ATLAS SAFEAI report to map real attack scenarios to specific techniques and then identify which mitigations apply. It is empirical, detailed, and directly actionable for red teams and blue teams alike.
OWASP Top 10 for LLMs focuses on the application layer, specifically on large language models and generative AI. Prompt injection holds the number one spot, and for good reason: it is the most exploited vector in deployed LLM applications today.
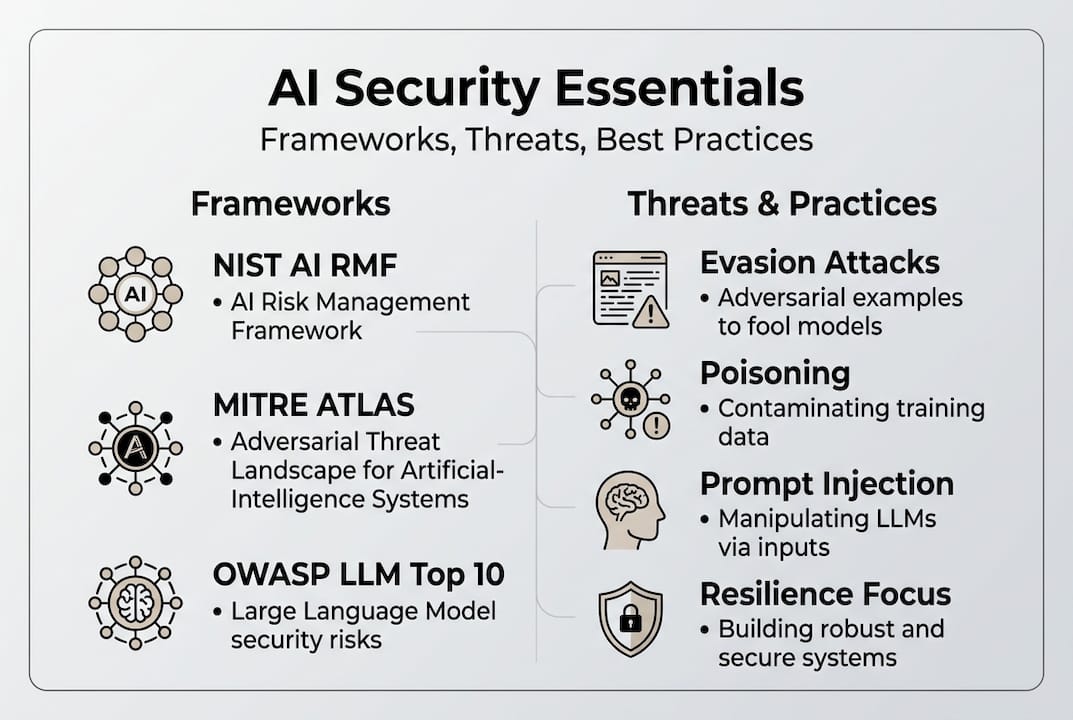
Here is how the three frameworks compare across key dimensions:
| Framework | Primary focus | Best used for | Threat coverage |
|---|---|---|---|
| NIST AI RMF | Governance and risk management | Enterprise policy and compliance | Broad organizational risk |
| MITRE ATLAS | Adversarial tactics and techniques | Red/blue team operations | 84 specific AI attack techniques |
| OWASP LLM Top 10 | Application-layer LLM risks | Developer and AppSec teams | Prompt injection, data leakage, insecure output |
A practical implementation sequence looks like this:
- Use NIST AI RMF to establish governance, assign ownership, and set risk tolerance thresholds.
- Apply MITRE ATLAS to threat-model your specific AI deployments and identify which attack techniques are most relevant.
- Use OWASP LLM Top 10 to harden any LLM-facing applications, APIs, or user interfaces.
- Map controls back to your existing security framework, whether that is CSF 2.0, ISO 27001, or SOC 2.
Understanding the advantages of real-time AI is valuable, but those advantages disappear fast if the underlying models are not secured against these documented attack patterns. If you want a deeper look at how different AI models handle risk exposure differently, that context matters when selecting which models to deploy in sensitive environments.
Threats and attack vectors: What to watch for in modern AI deployments
Frameworks give you structure. Threat knowledge gives you targets. Here is what the actual attack landscape looks like for organizations running AI in production.
Evasion and poisoning attacks are the two most foundational threat types. Evasion attacks manipulate inputs at inference time to fool a deployed model. Poisoning attacks corrupt training data before the model is ever deployed. Both can be executed as white-box attacks, where the attacker has full knowledge of the model architecture, or black-box attacks, where they only have query access. Key threats include evasion, poisoning, prompt injection, agentic AI overreach, model inversion, and supply chain vulnerabilities, and each requires a different defensive response.

Emerging threat vectors are where the landscape is evolving fastest:
| Threat | Description | Risk level |
|---|---|---|
| Promptware kill chains | Malicious prompt sequences that automate multi-step attacks through AI agents | Critical |
| RAG poisoning | Injecting malicious content into retrieval-augmented generation knowledge bases | High |
| Agentic AI overreach | Autonomous AI agents taking unauthorized actions due to excessive permissions | High |
| Model inversion | Reconstructing training data from model outputs, exposing sensitive information | Medium-High |
NIST frames adversarial threats across four axes: attacker knowledge (white-box vs. black-box), attack stage (training vs. inference), system exposure (open vs. closed), and model vulnerability (architecture-specific weaknesses). This four-axis model is useful for prioritizing which threats are most relevant to your specific deployment.
The ShadowRay and Morris II Worm cases are worth revisiting here. ShadowRay showed that AI infrastructure, not just models, is a target. Morris II showed that generative AI can be used as a propagation mechanism. Both cases involved attackers exploiting gaps that traditional security teams were not monitoring.
Pro Tip: Map every AI system you operate to NIST's four axes before you start threat modeling. It forces you to answer concrete questions about attacker access and model exposure that most teams skip.
For organizations evaluating top AI models in 2026, threat surface varies significantly by model type, deployment mode, and whether the model has agentic capabilities. A model with tool-use access and internet connectivity has a fundamentally different attack surface than a closed inference endpoint.
Practical mitigation strategies for defending AI systems
Knowing the threats is half the battle. The other half is building controls that actually hold up under real attack conditions. Mitigations include adversarial training, certified defenses, validation and sanitization, least-privilege, monitoring, and supply chain verification, and the best programs layer these rather than relying on any single control.
Here is what a layered mitigation approach looks like in practice:
- Adversarial training: Expose models to adversarial examples during training so they learn to resist manipulation. This improves robustness but typically reduces accuracy by 2 to 5 percent, a tradeoff your team needs to evaluate explicitly.
- Certified defenses: Use mathematically provable robustness guarantees for specific input ranges. These are computationally expensive but provide the strongest assurance for high-stakes applications.
- Input validation and sanitization: Inspect and filter inputs before they reach the model. For LLMs, this means prompt filtering, output validation, and guardrails that prevent injection payloads from executing.
- Least-privilege for AI agents: Agentic systems should have the minimum permissions needed for their task. An AI agent that can read files, send emails, and execute code is an attacker's dream if it gets compromised.
- Continuous monitoring: Deploy behavioral monitoring that flags anomalous model outputs, unusual query patterns, or unexpected data access. Static security testing is not enough for systems that change behavior based on input.
- Supply chain verification: Validate every third-party model, dataset, and ML library before it enters your environment. Use cryptographic signing and provenance tracking where possible.
Pro Tip: Run a red-team exercise specifically against your AI systems using MITRE ATLAS techniques before you go to production. Most security teams run red teams against infrastructure but skip the model layer entirely.
The NIST AI security report notes that 70% of MITRE ATLAS mitigations map to controls organizations likely already have in some form. The gap is usually in applying those controls specifically to AI workloads. Reviewing best AI practices and understanding AI model types for integration will help your team prioritize which controls apply to which deployment scenarios.
A fresh perspective: Why advanced AI security isn't about perfection—it's about resilience
Here is the uncomfortable truth most security vendors will not tell you: there is no such thing as a fully secured AI system. Adaptive attacks mean no perfect defenses exist, and organizations that chase zero-failure postures end up slower, more brittle, and less prepared for the attacks that actually land.
The organizations that handle AI security best are not the ones with the most controls. They are the ones with the fastest feedback loops. They run continuous red-team exercises, monitor model behavior in production, and treat every incident as a data point that improves their defenses. They overlay AI-specific controls onto frameworks like CSF 2.0 and NIST rather than building parallel security programs that nobody maintains.
The arms race between attackers and defenders in AI is real. Every new mitigation technique gets studied, and adversaries develop adaptive attacks to circumvent it. Aiming for resilience means accepting that some attacks will succeed and investing in detection, containment, and recovery rather than purely in prevention. Your AI security and privacy posture should reflect this reality: build systems that fail safely, recover quickly, and learn from every incident.
Taking the next step toward secure, enterprise-grade AI
Securing AI systems is not a one-time project. It is an ongoing operational discipline that requires the right platform, the right controls, and access to models you can actually trust.
Sofia🤖 is built with enterprise security at its core, including GDPR compliance, enterprise-grade encryption, and privacy controls designed for organizations that cannot afford to cut corners. With access to over 60 state-of-the-art AI models, including GPT-4o, Claude 4.0, and Gemini 2.5, all integrated into a single auditable platform, Sofia🤖 gives security teams the visibility and control they need to deploy AI responsibly. If your organization is ready to move from ad-hoc AI adoption to a structured, secure AI program, Sofia🤖 provides the foundation to do it right.
Frequently asked questions
What is advanced AI security?
Advanced AI security is a set of specialized practices for protecting AI systems and models from targeted, AI-specific threats across their full lifecycle, from data collection through production inference.
How is AI security different from traditional cybersecurity?
AI security uniquely addresses threats like adversarial attacks, model extraction, and prompt injection, which traditional security tools were never designed to detect or prevent.
What are the top frameworks for advanced AI security?
The three key standards are NIST AI RMF, MITRE ATLAS, and OWASP Top 10 for LLMs, each covering a different layer of AI risk from governance to application security.
What is the biggest threat to AI systems today?
Prompt injection is ranked number one by OWASP LLM Top 10 for 2025, making it the most prevalent and actively exploited threat in deployed generative AI applications.
Can organizations achieve perfect AI security?
No. Adaptive attacks ensure that no defense is permanent, which is why the goal must be resilience, rapid detection, and continuous improvement rather than an unachievable zero-failure standard.