
Selecting the right AI model for your organization is not a minor technical decision. It shapes how quickly your teams can automate workflows, how accurately your systems predict outcomes, and how smoothly new tools integrate with existing infrastructure. With dozens of model categories now available across supervised, unsupervised, generative, and architectural paradigms, the terminology alone can slow down even experienced technology leaders. This article cuts through that noise, mapping each major model type to real business scenarios and giving you a practical framework for evaluation and selection.
Table of Contents
- How to evaluate and select AI models
- Supervised learning models: Predicting and classifying
- Unsupervised learning models: Finding hidden patterns
- Reinforcement learning models: Optimizing decisions
- Generative vs discriminative models
- Architectures: CNNs, RNNs, Transformers, GANs, Diffusion
- Benchmarks and evaluation: Measuring performance in context
- Take your AI integration to the next level
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Main AI model types | Supervised, unsupervised, and reinforcement learning serve distinct business tasks. |
| Generative vs discriminative | Generative models create and augment content, while discriminative models excel at classification. |
| Architectural selection | Choosing the right architecture—CNN, RNN, Transformer, GAN—depends on your business goals and data. |
| Performance benchmarks | Benchmarks like MMLU and HumanEval guide evaluation for model adoption in organizations. |
How to evaluate and select AI models
Before you commit to any model, you need a structured evaluation lens. The most effective technology professionals assess five core criteria: task fit (does the model solve the actual problem?), data availability (do you have enough labeled or unlabeled data?), accuracy requirements (what error rate is acceptable?), scalability (can it handle production load?), and integration complexity (how much engineering effort does deployment require?).
These criteria are not independent. A model with outstanding accuracy may fail in production if it cannot scale or if your data pipeline is not mature enough to feed it consistently. That tension is why AI model selection deserves a structured process rather than a quick benchmark comparison.
One important trend reshaping this decision is the move toward hybrid and multi-model systems, where organizations combine specialized models rather than relying on a single general-purpose solution. This approach improves flexibility and lets each model handle the task it was designed for.
- Task fit: Match model type to the specific business problem
- Data readiness: Audit labeled vs. unlabeled data volumes before selecting
- Accuracy threshold: Define acceptable error rates per use case
- Scalability: Stress-test under realistic production conditions
- Integration: Evaluate API availability, latency, and security requirements
Pro Tip: Always pilot models on real business data before full deployment. Benchmark scores on public datasets rarely translate directly to your specific domain or data quality.
Supervised learning models: Predicting and classifying
Supervised learning is the workhorse of enterprise AI. These models train on labeled datasets, meaning every input has a known correct output, and they learn to map new inputs to predictions. Common model types include Logistic Regression for binary outcomes, Support Vector Machines for high-dimensional classification, and Decision Trees for interpretable rule-based decisions.
The primary supervised learning paradigm excels when you have structured data and a clearly defined target variable. Think sales forecasting, credit risk scoring, customer churn prediction, or fraud detection. These are problems where historical labeled data is abundant and the cost of a wrong prediction is quantifiable.
"Traditional ML powers most enterprise predictions, and supervised models remain the most deployed category in production business systems."
Strengths include high accuracy on well-defined tasks, interpretability (especially with tree-based models), and a mature ecosystem of tools. The main caveat is data dependency: poor labeling quality directly degrades model performance. Investing in AI practices for efficiency means treating data labeling as a first-class engineering task, not an afterthought.
- Logistic Regression: Fast, interpretable, ideal for binary classification
- Decision Trees and Random Forests: Handle mixed data types, easy to audit
- Support Vector Machines: Strong on smaller, high-dimensional datasets
- Gradient Boosting (XGBoost, LightGBM): Top performers for tabular business data
Pro Tip: For structured business problems like sales pipeline scoring or risk assessment, start with gradient boosting models. They consistently outperform simpler alternatives on tabular data and are well-supported in most business productivity with AI platforms.
Unsupervised learning models: Finding hidden patterns
Not every business problem comes with labeled answers. Unsupervised learning models work on raw, unlabeled data to surface structure that was not previously visible. This is where you discover customer segments you did not know existed, detect anomalies in transaction streams, or reduce the dimensionality of complex datasets for downstream analysis.
The unsupervised learning paradigm covers clustering algorithms like K-means and Hierarchical Clustering, dimensionality reduction techniques like Principal Component Analysis, and anomaly detection methods. These tools are especially valuable in early-stage data exploration or when labeling data at scale is cost-prohibitive.
"Unsupervised models for clustering and anomaly detection open up discovery workflows that labeled data approaches simply cannot support."
Practical applications include market segmentation, network intrusion detection, and document grouping. For teams working with large volumes of unstructured content, pairing unsupervised clustering with document analysis AI creates powerful discovery pipelines. Similarly, image analysis AI workflows often use unsupervised pre-training to build feature representations before fine-tuning on labeled tasks.
- K-means clustering: Fast, scalable, good for customer segmentation
- Hierarchical clustering: Reveals nested groupings without predefined cluster count
- PCA: Reduces feature space, speeds up downstream model training
- Isolation Forest: Efficient anomaly detection in high-volume data streams
Reinforcement learning models: Optimizing decisions
Reinforcement learning takes a fundamentally different approach. Instead of learning from a fixed dataset, an RL agent learns by interacting with an environment and receiving reward signals based on its actions. Over time, it discovers the policy that maximizes cumulative reward.
Reinforcement learning is the right choice when the problem involves sequential decision-making in dynamic environments. Robotics, logistics routing, supply chain optimization, and real-time bidding systems are classic applications. The tradeoff is sample inefficiency: RL models typically require far more interactions to converge than supervised alternatives.
Frontier models are now saturating traditional benchmarks, which is pushing evaluation toward agentic and multi-step task performance, exactly the domain where RL-trained systems shine. For organizations exploring real-time AI for business, RL-based optimization engines can deliver measurable efficiency gains in dynamic operational contexts.
- Sequential decision-making: RL outperforms static models in changing environments
- Reward shaping: Careful design of reward functions is critical to useful behavior
- Simulation requirements: Most RL deployments need a simulation environment for safe training
- Compute intensity: Budget for significant GPU resources during training phases
Generative vs discriminative models
This distinction cuts across the supervised/unsupervised divide and directly affects what a model can produce. Generative models learn the joint probability distribution of inputs and outputs, meaning they can generate new data samples. Discriminative models learn the conditional probability of an output given an input, making them optimized for classification and prediction.
Generative models learn joint distributions while discriminative models focus on decision boundaries. In practice, this means generative models handle missing data more gracefully and can augment training sets, while discriminative models tend to be more robust to noisy inputs and deliver sharper classification accuracy. You can also explore the model differences in depth for technical implementation guidance.
| Feature | Generative models | Discriminative models |
|---|---|---|
| Primary task | Data generation, augmentation | Classification, prediction |
| Data handling | Handles missing data well | Robust to noisy inputs |
| Typical use cases | Content creation, simulation | Fraud detection, risk scoring |
| Training complexity | Higher | Lower |
| Output type | New data samples | Class labels or probabilities |
For AI in content creation, generative models are the clear choice. For AI marketing optimization tasks like audience targeting or conversion prediction, discriminative models typically deliver more reliable results.
Pro Tip: Use generative models for creative augmentation and synthetic data generation. Use discriminative models where you need consistent, auditable business rules and low false-positive rates.
Architectures: CNNs, RNNs, Transformers, GANs, Diffusion
Model type tells you the learning paradigm. Architecture tells you how the model is built internally, and that determines what kinds of data it handles best. Understanding architecture helps you match vendor offerings to your actual workloads.
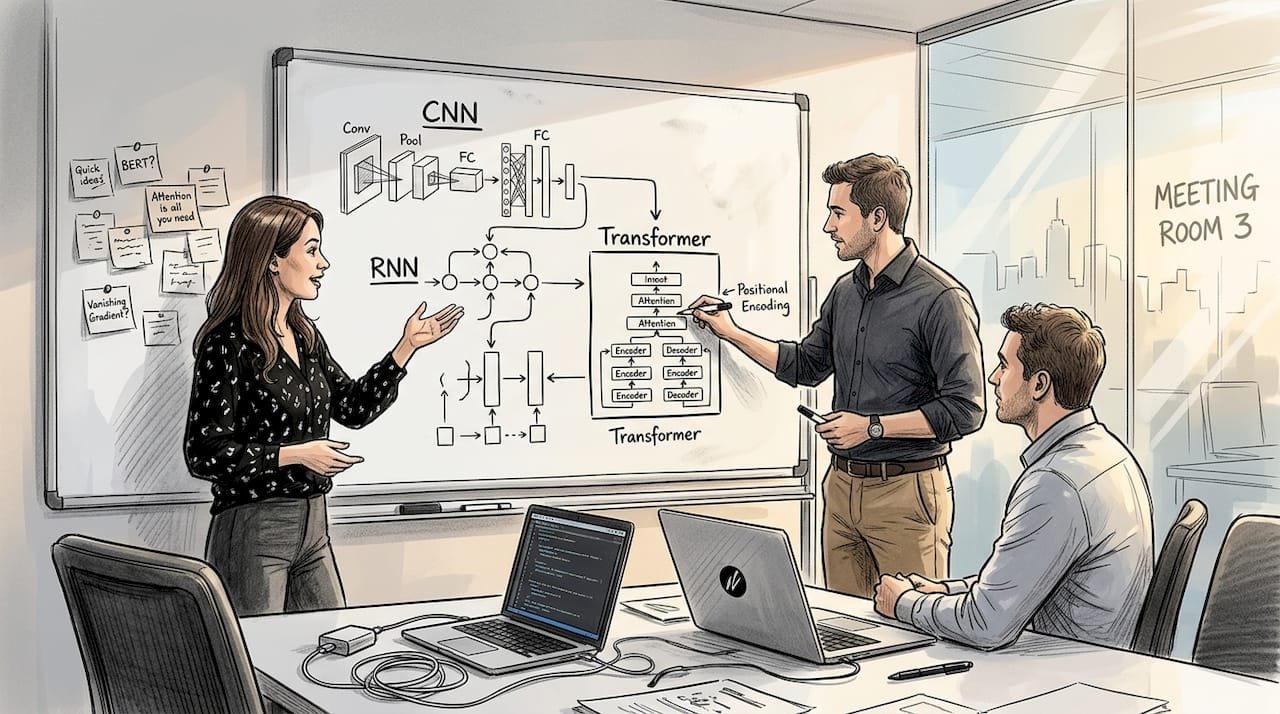
Architectural types span Convolutional Neural Networks for image and vision tasks, Recurrent Neural Networks and LSTMs for sequences and time series, Transformers powering most modern large language models, GANs for adversarial content generation, and Diffusion Models for high-quality image synthesis. Hybrid architectures like Mamba-Transformer Mixture of Experts are emerging as the next frontier for efficiency at scale.
| Architecture | Primary use case | Integration ease |
|---|---|---|
| CNN | Image classification, vision | High (mature tooling) |
| RNN/LSTM | Time series, NLP sequences | Medium |
| Transformer | LLMs, agentic AI, text | High (API-first) |
| GAN | Synthetic data, image gen | Medium |
| Diffusion | High-quality image synthesis | Medium |
For teams building content creation with AI pipelines, Transformer-based models offer the broadest capability. For visual workflows, CNNs and Diffusion models complement each other well, as covered in the image analysis AI guide.
Benchmarks and evaluation: Measuring performance in context
Knowing model types is only half the equation. You also need reliable ways to measure whether a model actually performs in your context. The most widely used benchmarks include MMLU for broad language understanding, HumanEval for code generation, GSM8K for mathematical reasoning, and SWE-Bench for software engineering tasks.
The challenge is that frontier models saturate traditional benchmarks rapidly, sometimes within months of a benchmark's release. This forces evaluation to shift toward agentic, multi-step, and domain-specific assessments that better reflect real business conditions. You can track frontier benchmarking trends to stay current on which evaluations carry the most signal.
"AI systems master new benchmarks faster than ever. Models like o1 use inference-time compute scaling to achieve gains that standard training alone cannot produce."
For practical deployment, contextual evaluation matters more than leaderboard rankings. Test models on your actual data, your actual tasks, and your actual latency requirements. Teams managing AI document review workflows should build internal evaluation sets that reflect the document types and decision complexity they face daily.
- MMLU: Tests broad language and reasoning across 57 subjects
- HumanEval: Measures functional code generation accuracy
- GSM8K: Evaluates multi-step mathematical problem solving
- SWE-Bench: Assesses real-world software engineering task completion
- Internal benchmarks: Always the most reliable signal for production decisions
Take your AI integration to the next level
You now have a clear map of AI model types, architectures, and evaluation methods. The next step is putting that knowledge to work inside your organization, and that requires access to the right models without the overhead of managing dozens of separate integrations.
Sofia🤖 gives technology professionals and business teams direct access to over 60 state-of-the-art AI models, including GPT-4o, Claude 4.0, and Gemini 2.5, all from a single platform. Whether you need supervised model outputs for structured business predictions, generative capabilities for content workflows, or document and image analysis for operational tasks, Sofia🤖 consolidates those capabilities with enterprise-grade security, GDPR compliance, and team collaboration tools built in. You can pilot, compare, and deploy AI models without spinning up separate infrastructure for each one.
Frequently asked questions
What are the core types of AI models?
The primary types are supervised, unsupervised, and reinforcement learning, each defined by how the model interacts with data and feedback during training. Generative and discriminative models represent a separate but overlapping classification based on what the model outputs.
Which AI model type is best for content creation?
Generative models like Transformers and GANs are purpose-built for augmenting and generating creative content at scale. Discriminative models can support content targeting but are not designed for generation tasks.
How do businesses measure AI model performance?
Organizations use standardized benchmarks like MMLU, HumanEval, and GSM8K as starting points, then layer in context-specific evaluations built from their own data and workflows.
What's the advantage of hybrid or multi-model AI systems?
Hybrid systems combine the strengths of multiple architectures, allowing each model to handle the task it was optimized for while improving overall adaptability across diverse business use cases.